MQ个人理解
口述MQ
个人口述:MQ 是Message Queue,消息队列。它在我目前的理解就是一个中间件,核心好处:应用解耦、异步提速、削峰填谷。
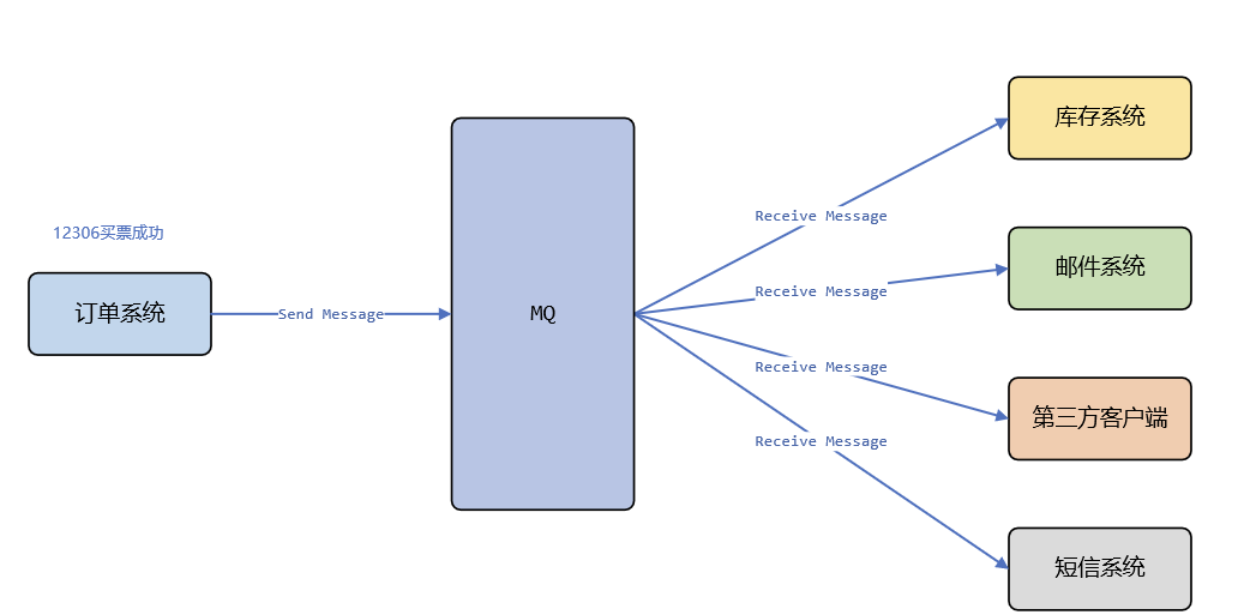
首先讲一下应用解耦,我拿12306买票这个场景举例子。正常设计业务会用户下单,下单以后扣除库存,发送邮件,发送短信,通知第三方。假设没有MQ进行应用解耦会出现的问题。1、产品经理加功能了,说用户下订单以后需要通知微信小程序,那你就要去订单系统中改代码,如果又多了很多下单以后的功能呢?非常不合理,要频繁更新代码,也很有可能将无bug的代码,增加功能增加出bug来。2、如果有一天短信系统挂了,用户下单了以后短信服务挂了,用户收不到短信,也没有扣除库存,也没有收到邮件。邮件系统好好的,因为短信系统的问题影响了,这也不合理。上面的两个原因都是因为系统之间耦合度太高了,通过MQ可以怎么做,首先上面的各种系统,其实就是在订单产生数据以后才有的,那我们可以当用户下单以后,通知给MQ,告诉它用户下单了,MQ再去通知其他的服务,可以扣减库存了,可以发送短信了。
第二个异步提速,假设我们不用MQ,那么我们的代码必然耦合在一起,下单成功后,依次调用这几个系统,然后同步等到他们的响应才能返回给用户是否成功的结果。假设每个系统耗时200ms,那么就得花费800ms,再加上下单的耗时就非常的慢,用户体验不佳。说再直白点就是因为是同步有点像串行化执行。但是其实在应用解耦的时候,我们就发现了,当下单以后通知MQ,其他系统订阅到MQ下单的消息,开始执行,其他系统是有点像类并行的。像下单的场景,用户最关心的是用户有没有下单成功,有没有买到票,通知什么的是次要的,那我们就可以当下单成功以后将消息发给MQ,并直接返回给用户下单成功了。其他模块再收到消息,执行他们该执行的任务。这样大大缩短了整体业务的耗时,对用户来说其实只消耗了下单成功的时间,通知的时间用户并不是最在乎的。再拿数据来说用户下单花费200ms,用户直接收到了下单成功的消息。MQ再通知其他系统,其他系统耗时都是200ms。那么整体耗时也就在400ms左右。因为MQ性能很好,通知和消费消息耗时非常短。
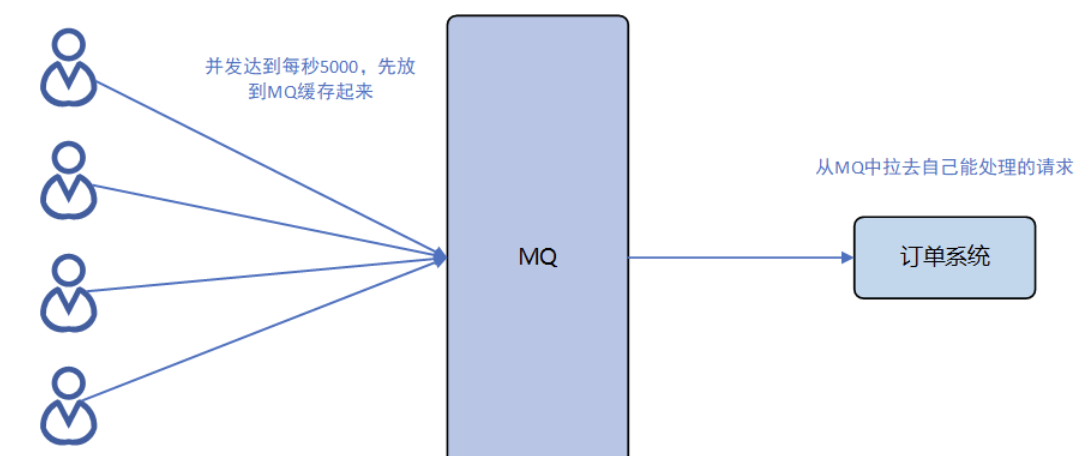
第三个削峰填谷,这个字面没有那么好理解,我们还是拿卖票这个场景解释,平常订票的时候QPS可能比较低,如果没有MQ,单靠订单系统也能处理,如果在国庆和假期旺季,抢票的人非常多,并发量会高很多,订单系统就扛不住了。如果不用MQ,我们可能会设置集群保证高可用。但是如果有MQ,因为MQ的吞吐能力非常强,我们可以设计高可用的MQ,我们可以把订单消息先放MQ缓存起来,把流量高峰削弱(削峰),这样订单系统就避免了高并发的请,再让订单系统去MQ慢慢拉消息,处理请求。这样一来,高峰期积压的消息也终将被消费完,可以叫做填谷。
口述RabbitMQ
个人口述:Rabbit MQ是MQ的一种,也是当前比较主流的MQ,优点是时效性,可靠性好。首先MQ上面也说了,是可以接受消息,并广播发出去。那肯定需要把消息进行存储,RabbitMQ的核心之一Queue。消息队列本质上就是一个类似于链表的独立进程,链表里的每个节点就是一个消息。它在生产者和消费者之间,在流量高峰的时候暂存数据,再慢慢消费数据就是之前说的削峰填谷。Queue就是刚刚说的类似链表的进程,消息也分了很多种类,所以我们的Queue也可以给他不同的命名用来存放不同的消息。每个Queue又是独立的进程,某个进程挂了互相不影响。有的时候我们一个消息可能要发给多个Queue,这个时候Exchange就出现了,它就相当于一个交换机可以定制消息路由分发策略来将消息分发给不同的Queue,生产者会携带RoutingKey给Exchange,它会通过RoutingKey和bindingKey投放给对应的Queue。刚刚说的路由方式和绑定关系,我们称为元数据。
RabbitMQ有哪些功能,死信队列,延时队列,优先级队列。
第一个死信队列,死信队列是用来存放一些因为某些原因没有正常被消费的消息的队列。它的核心的避免数据的丢失,并为异常消息提供专门的处理通道,保证消息的可靠性。消息成为死信的条件。有消息过期了,队列满了,消息被拒绝了并且requeue设置false不重新入队,该队列成为死信,又通过**dead-letter-exchange**绑定了一个交换机,该交换机就称为死信交换机,那死信交换机的作用就是存放死信队列的。
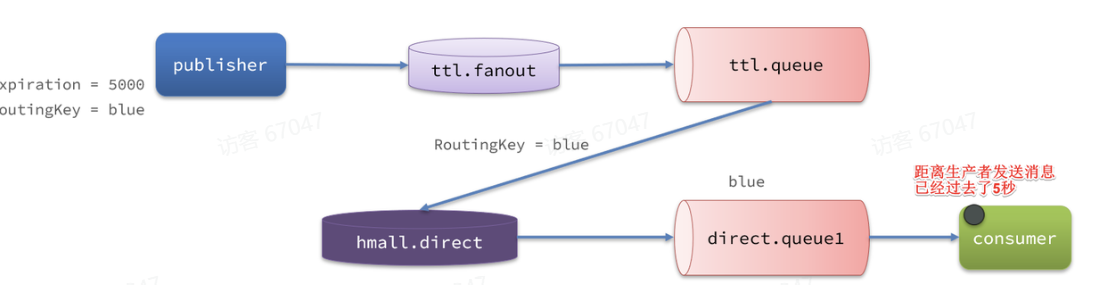
第二个延时队列。RabbitMQ 的延时队列是一种特殊的消息队列,用于实现 “消息发送后,不立即被消费,而是在指定时间后才被处理” 的需求。用户下单后若在 30 分钟内未支付,需要自动取消订单并释放库存。此时可将订单信息发送到延时,30 分钟后消费消息执行取消逻辑。那我们MQ怎么实现延时队列,MQ本身是没有延迟队列的,但是我们能通过死信队列和死信交换机实现延迟消息的发送。如下图,publisher是生产者,发送一个消息设置过期时间5s,RoutingKey为blue,Exchange为fanout类型,此时消息先发送到ttl.fanout,又转发给ttl.queue。ttl.queue绑定了死信交换机hmall.direct,hmall.direct事先通过BindingKey=‘blue’和direct.queue1绑定了。此时5s到了,消息过期了,ttl.queue携带RoutingKey发送给hmall.direct,hmall.direct发现ttl.queue的RoutingKey和direct.queue1的BindingKey匹配,于是消费者收到消息,此时离生产者发送消息那一刻过去了5秒。一般会使用DelayExchange插件搭配springAMQP使用。
第三个优先级队列,应用场景在比如普通用户和会员用户同时发起请求给A服务,A服务会转发给B服务,B服务是算法服务,我们想优先处理会员用户的请求。MQ如何实现的,队列声明的时候要先通过x-max-priority参数设置最大优先级别<=10,生产者发送消息的时候,在消息属性中添加priority字段,指定具体优先级需要小于等于队列最大优先级别。消费者监听优先级队列,队列会自动将高优先级消息排在队头,消费者会优先获取并处理高优先级消息。这样在消息堆积的时候就会优先处理高优先级的消息。
口述可靠性
个人口述:消息从生产者到消费者的每一步都可能导致消息丢失:
- 发送消息时丢失:
- 生产者发送消息时连接MQ失败
- 生产者发送消息到达MQ后未找到Exchange
- 生产者发送消息到达MQ的Exchange后,未找到合适的Queue
- 消息到达MQ后,处理消息的进程发生异常
- MQ导致消息丢失:
- 消息到达MQ,保存到队列后,尚未消费就突然宕机
- 消费者处理消息时:
- 消息接收后尚未处理突然宕机
- 消息接收后处理过程中抛出异常
-
首先、说一下生产者怎么一定能把消息发送到MQ,当生产者发送消息的时候,出现网络故障,导致和mq连接中断。springamqp引入了重试机制,当rabbitTemplate和mq连接超时的时候,修改配置文件可以配置重试次数和重试间隔时间。除了网络问题,还有发送消息丢失的其他情况,rabbitmq引入了生产者确认机制,包括Publisher Confirm和Publisher Return,确认消息是否到达了路由,是否从路由到了队列。confirm机制包括ack和nack,它每次发送消息都要添加,因为不同的消息处理逻辑不一样,return机制包括return只用全局配置一次。但是一般不使用mq生产者确认机制比较消耗性能。只要编程人员队列名和路由名不填错,连接没问题,一般不会有问题。MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
-
第二、MQ的可靠性,消息如果到达mq以后没有及时保存,也会导致消息丢失。默认mq数据是内存存储的临时数据,重启以后数据就丢失了,所以我们要给rabbitmq的数据配置持久化,交换机、队列、消息都要配置持久化。❗如果同时开启了生产者确认机制和持久化,mq会在持久化以后返回ack回执。为了减少IO次数,mq并不是逐条持久化到数据库,而是每隔一段时间批量把数据持久化到erlang的mnesia数据库。
-
第三、lazyqueue,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
消费者宕机或出现网络故障
消息发送量激增,超过了消费者处理速度
消费者处理业务发生阻塞
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为成为PageOut. PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
接收到消息后直接存入磁盘而非内存
消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
支持数百万条的消息存储 -
消费者可靠性,mq提供了消费者确认机制,当消费者处理消息结束后,应该向mq发送一个回执告诉mq消息处理状态,有三种可选值ack,成功处理,删除消息 nack处理失败 再次投递消息 reject处理失败并拒绝消息 删除消息。springamqp通过配置文件设置了ack处理方式,如果业务异常返回nack,消息处理或类型检验异常,返回reject。当消费者出现一场后消息会不断从入队再重新发送给消费者,如果依然出错会再次入队,直到处理成功为止。极端情况会一直无法执行成功消息就会一直循环,spring提供了消费者失败重试机制,可以设置失败重试次数。当从事达到最大次数的时候spring会返回reject消息会被丢弃。但是这对于消息可靠性要求较高的业务场景不太好,因此spring允许我们自定义重试次数耗尽后的消息处理策略,通过messageRecovery接口定义,有三个实现,分别是直接reject,返回nack重新入队,将失败消息投递到指定交换机,显然第三种比较好,后续可以人工专门处理该队列中存放的失败消息。
业务的幂等性,业务的幂等性是指同一个业务执行多次和执行一次给业务状态影响是一致的。但是像数据更新往往不是幂等性的,重复执行会有不一样的结果。代入我们mq中,其实就是消息因为某种原因被消费者重复消费了导致出现了问题。比如这个场景,生产者发送支付订单消息,此时修改了订单状态为已支付并扣减库存,但是因为网络故障生产者没有收到得到确认,生产者就会隔一段时间再发送一次请求,但是在请求发送之前,用户退款了,订单修改成已退款,此时消息发过来又改成已支付就出现问题了。解决方式分两种,第一种携带业务id,生产者给消息携带id,当消费者收到消息把id存入数据库中,生产者再发送消息过来,判断数据库中是否有该id,有的话就是判断重复消费。第二种是业务判断,根据业务本身的逻辑或状态判断是否是重复的请求或消息1,比如修改订单的时候判断订单id状态是否是已支付,库存是否已经扣减过。最后就是兜底方案,加假如MQ真的消息通知失败了,我们要设置兜底方案,比如MQ通知不一定发送到交易服务,那交易服务就可以主动去查支付状态,这里可以设置spring task定时任务定期查询。





